



Работая с A/B-тестами, мы замечали, что результаты, которые мы получаем, не всегда выглядят достоверными. Прочли в блоге Hookedondata.org гид по A/B-тестам, узнали важные нюансы A/B-тестирования, перевели статью и — делимся с вами.
Emily Robinson, Warby Parker
Работая в Etsy, я имела возможность воспользоваться очень надёжной системой A/B-тестирования. Etsy проводила A/B-тестирование уже более шести лет, а к моменту, когда я уходила, над внутренней системой экспериментов под названием «Катапульта» работало уже пять инженеров на полную ставку. Каждое утро меня встречала домашняя страничка с экспериментами, которые Etsy проводила в последние 4 года. Кликнув по одному из них, я получала краткое описание того, что тестировал эксперимент (обычно написанное продакт-менеджером). Все ключевые показатели, например, коэффициент конверсии и коэффициент добавления в корзину, уже были рассчитаны. Можно легко было узнать показатели для любого события, произошедшего на сайте.
И всё же иногда я проводила большую часть своего времени, работая над экспериментами, даже несмотря на то, что я старалась не работать более чем над тремя-четырьмя сразу. Почему же это занимало столько времени, ведь многое уже было сделано до меня.
Концепция A/B-тестирования кажется довольно простой. Классический пример: изменить цвет кнопки и измерить, изменяется ли количество кликов. Предполагая, что при сборе данных всё работает верно, вам остаётся только запустить тест с пропорциями, а если этот тест уже готов, то зачем вам вообще нужен специалист по работе с данными?
Он может понадобиться, если вы хотите поэкспериментировать с новыми технологиями (типа multi-armed bandits), но как классическое A/B-тестирование могло стать такой проблемой?
К сожалению, «собрать числа просто, собрать числа, которым вы сможете доверять, — сложно». Многое в A/B-тестировании может пойти не так, и это не будет для вас очевидно.
Я заметила, что аналитики и специалисты по работе с данными часто сталкиваются с трудностями в A/B-тестировании. Поэтому в моей статье собраны рекомендации, которые помогут вам избежать самых распространённых ошибок при запуске системы A/B-тестирования в вашей компании.
Принцип 1. Использовать только один ключевой показатель
Можно контролировать несколько метрик, но целью должен быть только один показатель. Доход — не самая лучшая метрика, поскольку будет слишком велик разброс полученных значений. Я рекомендую выбирать пропорционные метрики (Proportion Metrics — такой термин больше нигде не используется, кроме, как автором статьи. — Прим.пер.). Потому что, во-первых, вас должно интересовать, сколько людей производят действие, а не то, как часто они его производят. Во-вторых, в таком случае вам не придётся думать о стандартных отклонениях и выбивающихся из паттерна значениях.
Почему только одна метрика? Потому что, занимаясь сразу несколькими, вы в результате получите рост ложноположительного результата. Есть методы коррекции, но в результате всё меньше шансов будет увидеть разницу между тестируемыми экземплярами.
Кроме того, ориентируясь на один показатель, проще принять решение по результатам теста.
Принцип 2. Использовать для расчёта статистической мощности специальный калькулятор
Частая ошибка в запуске тестов — запустить его на таком маленьком трафике, что для достоверного результата за одну неделю придётся получить очень большую разницу в значениях метрики. Во избежании этого воспользуйтесь калькулятором A/B-тестов для определения времени, которое потребуется, чтобы увидеть изменение метрики на X%. Для пропорционных метрик, то есть тех, что выражены процентами, вам нужно будет знать текущий показатель. Для количественных метрик — её значение и стандартное отклонение.
Также вы должны представлять:
- сколько пользователей приходит ежедневно на тестируемую страницу;
- какой процент изменений вы хотели бы получить;
- сколько людей вы будете отправлять на тестовый вариант (50/50? 72/52?);
- показатель достоверности (обычно 95 или 90%).
Для расчётов можете использовать калькулятор www.experimentcalculator.com.
Обычно после этого происходят две вещи. Вы либо узнаёте, что на получение достоверного результата вам потребуется несколько дней или недель. Либо видите, что понадобится три года пять месяцев и 23 дня. Тогда вы либо решаете сосредоточиться на другой метрике, либо повышаете показатель изменений, которые хотите установить. Например, решаете, что вас интересует изменение конверсии только на 10%, а 5% не имеют значения.
Если вы хотите узнать о мощности больше, можете изучить замечательный вступительный пост от Джулии Сайлдж. Она даже создала приложение, которое поможет посчитать статистическую мощность.
Принцип 3. Выдерживать запланированную длительность эксперимента
В первые несколько дней, конечно, надо следить за ним, чтобы убедиться, что ничего сломалось, но длительность его должна быть не меньше, чем вы планировали в своём расчёте мощности. Не останавливайте эксперимент, как только увидите какие-то достоверные изменения или вы получите кучу ложных срабатываний, как в описании A/B-тестирования у Дэйва Робинсона.
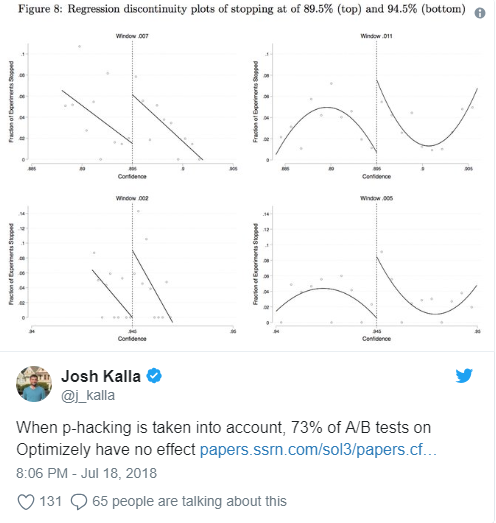
Принцип 4. Обращать больше внимания на доверительные интервалы, чем на p-значение
P-значение (P-value — статистическая значимость. — Прим.пер.) показывает, насколько можно быть уверенным, что различия в вариантах не являются случайными, то есть не являются статистической погрешностью. Эта величина подробно описана в статье GoPractice в разделе «Статистическая значимость простыми словами».
По этому параметру можно оценить, насколько правильно были выбраны условия проведения тестирования: размер контрольных групп, период проведения теста и так далее. Доверительный интервал показывает, что оцениваемое значение с заданной вероятностью находится в этом интервале.
На основании этого параметра мы можем оценить точность результатов нашего теста, прежде чем делать какие-то выводы или предпринимать какие-то действия.
Чем шире доверительный интервал, тем меньше точность теста.
Принцип 5. Не запускать кучу тестирований
Предположим, вы хотите изменить дизайн домашней страницы, и ваши дизайнеры придумали шесть вариантов. Как же выбрать? Что ж, для этого и существует A/B-тестирование, верно? Нет, не верно. Вы снизите свою возможность обнаружить статистический эффект, так как в каждой группе будет меньше людей. Вы также повысите вероятность ложного срабатывания, если просто протестируете контрольную группу относительно каждой экспериментальной группы. Опыт говорит, что правильнее придерживаться одной экспериментальной и контрольной группы и не делать больше четырёх групп в целом (контрольной и трёх вариативных).
Принцип 6. Не искать различия в каждом возможном сегменте
Если ваш тест в целом не сработал, то заманчиво надеяться, что он всё-таки сработал — просто не для всех. Или даже если ваше A/B-тестирование сработало, вы можете захотеть узнать, было ли это вызвано значительным изменением в одном сегменте. Помогли ли мы американским посетителям? Новым посетителям? Субботним посетителям? А дальше вас будет ждать безумие от ложных срабатываний в бесконечном множестве тестирований. Если же вы думаете, что разница действительно есть, проведите отдельные тесты (например: один для новых пользователей, один для вернувшихся).
Принцип 7. Проверять, нет ли искажений
Искажения — это несоответствие соотношения выборок, где сплит между вашими вариативными группами не соответствует тому, что вы планировали. Например, вы хотели разделить людей между контрольной и экспериментальной группой 50/50, а через несколько дней обнаруживаете что 40% находятся в экспериментальной группе, а 60% — в контрольной. Это проблема.
Если у вас много пользователей, то даже соотношение 50,1% к 49,9% уже может указать вам на проблему в ваших настройках. Чтобы проверить, есть ли у вас проблемы, запустите тест пропорции и проверьте, что ваше p-значение не меньше, чем 0,5%. К сожалению, причину искажения бывает трудно обнаружить. Но можно сразу проверить, зависят ли различия в выборках от используемого браузера, страны пользователя или другого человеческого фактора.
Принцип 8. Не усложнять свои методы
Возможно, у вас есть инженеры, которые читали о тестировании с «многорукими бандитами», статистики-ботаники, которые хотят использовать Байесовские методы, или менеджерах по продуктам, которые хотят, чтобы ключевая метрика была сложной поведенческой последовательностью. Если вы только начинаете использовать методы A/B-тестирования, сосредоточьтесь на том, чтобы правильно делать основные, часто используемые методы. И даже через несколько лет, лучше инвестируйте в экспериментальный дизайн и обучение, а не в модные статистические методы.
Принцип 9. Не выпускать изменения, просто потому что «они не навредят»
Они могут иметь очень небольшой негативный эффект, который не заметен сразу, но в долгосрочной перспективе сильно повлияет на продукт. Если раздумываете, стоит ли осуществить какое-то «нейтральное» изменение, в первую очередь посмотрите на неключевые метрики. Если на них изменение повлияло негативно, возможно, стоит откатиться. Если негативного влияния не было, здесь уже вопрос к вашей продуктовой интуиции. Будут ли эти изменения полезны пользователям? Станут ли они основой для ваших будущих изменений?
Принцип 10. Найти аналитика, полностью вовлечённого в процесс
Как однажды сказал сэр Р. А. Фишер: «Проконсультироваться со статистиками после завершения эксперимента — это просто попросить их провести вскрытие. Они, возможно, могут сказать, от чего умер эксперимент». Если команда пытается привлечь научного аналитика уже после начала эксперимента, она может обнаружить, что не существует данных для измерения ключевого показателя, или есть дефект дизайна, или этого теста недостаточно — всё это означает, что команда не может сделать никаких выводов.
Принцип 11. Включать в анализ только тех людей, которые могли быть затронуты изменениями
Если в эксперименте есть пользователи, на работу которых изменение не повлияло, вы просто создаёте ненужные помехи и уменьшаете возможность обнаружения эффекта. Например, если вы изменяете макет страницы поиска, добавьте в эксперимент только тех пользователей, которые посещают страницу поиска. В более сложном примере, предположим, вы хотите поэкспериментировать с изменением порога предложения бесплатной доставки (отображаемого только тогда, когда они соответствуют критериям) с 35 до 25 долларов. Вы должны поставить в эксперимент только тех пользователей, размер корзины которых от 25 до 35 долларов, потому что только они увидят какие-то изменения в контрольной и экспериментальной группах. Соответственно, начинайте отслеживать свои метрики только после того, как пользователь увидит соответствующую страницу. Представьте, что вы запускаете эксперимент на странице поиска, кто-то посещает ваш сайт и совершает покупки на главной странице, а затем переходит на страницу поиска, входя в эксперимент. Вам будут неинтересны его действия до попадания на страницу поиска, так как они не могли быть результатом вашего изменения.
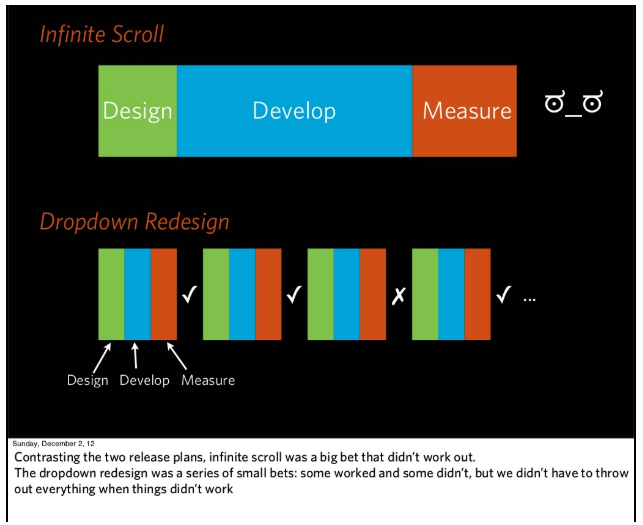
Принцип 12. Сосредоточиться на небольших, постепенных тестах, которые меняют одну вещь за шаг
Очень заманчиво запускать большие эксперименты или связку маленьких в надежде, что они приведут к большим результатам. Но часто вы инвестируете в это тонны усилий, а потом узнаёте, что ваше изменение не работает. И тогда трудно понять, что именно произошло: только часть эксперимента потерпела неудачу или это было взаимодействие нескольких изменений? Лучшее решение — разделить большие эксперименты на более мелкие тесты.
Дэн Маккинли, бывший главный инженер Etsy, приводит отличный пример этой проблемы в своей презентации о непрерывных экспериментах. Его команда провела недели, работая над включением infinite scroll для страницы поиска. Но когда они запустили A/B-тестирование, то обнаружили что infinite scroll показывает плохие результаты. Их первой реакцией было предположение, что это, должно быть, какая-то ошибка, но когда они нашли ошибку и исправили её, результаты остались неизменными. Поэтому они вернулись на шаг назад — к тому, почему они решили, что бесконечный скролл будет лучше. Во-первых, действительно ли большее количество элементов на странице лучше? Когда они изменили только количество элементов на странице поиска, то обнаружили, что получили большее количество кликов, но такое же количество покупок. Во-вторых, было ли столь значительным улучшением получение быстрых результатов поиска? Нет, искусственное замедление поиска ничему не повредило. Если бы они сначала проверили эти гипотезы, не пришлось бы инвестировать в бесконечный скролл.
В нашем Телеграм-канале Маркетинг за три минуты мы пересказываем самые интересные материалы про онлайн-маркетинг в формате постов-трёхминуток — подписывайтесь и будьте в курсе. А если вы хотите поболтать и поделиться своими мыслями, приходите к нам в CRM-Chat.






