Бизнесу важно знать, кто твои покупатели, сколько им лет, где они живут и что любят. Эти характеристики помогают успешно сегментировать покупателей. Но не менее важно быть в курсе, что именно и как они покупают. С этим поможет анализ потребительской корзины с точки зрения подбора товаров из разных категорий.
Он позволит:
- повысить эффективность маркетинговых кампаний;
- оптимизировать ассортимент и запасы;
- создать бизнес-шаблоны покупок.
Самый забавный пример такого анализа — это анализ товарных корзин в компании Teradata, где самой популярной оказалась пара «пиво — подгузники». Без специальных алгоритмов такую связь выявить очень тяжело.
Функционал для подбора товарных пар есть во многих платформах. Они используют собственные решения для подбора. Но на их настройку уходит много времени, к тому же модели потребуется не меньше двух недель на обучение.
Наше решение позволит собрать такую пару за несколько часов и частично автоматизировать ручные рекомендации.
Алгоритм подбора товарных пар
Мы используем для подбора алгоритмы поиска ассоциативных правил, то есть ищем логические взаимосвязи между связанными данными. В нашем случае правило звучит как: «Если в корзине есть товар A, то с некой вероятностью будет и товар B».
Чем больше товаров, тем больше получится товарных пар. При этом товарная пара не обязательно состоит из двух товаров, это могут быть три, четыре, пять товаров и так далее. Количество пар вычисляется по формуле: 2^n — 1 , n — количество товаров. Например, если у вас 10 товаров, то товарных пар будет 210 — 1 = 1023 Поэтому важно понимать, что не все полученные правила будут статистически значимы.
Чтобы получать только реальные правила, необходимо использовать два самых важных критерия — поддержка и достоверность.
- Поддержка (support) — это % транзакций, содержащий определённый товар или набор товаров.
Используется для выявления часто встречающихся товаров.
- Достоверность (confidence) — это вероятность того, что если есть товар А, то будет и В.

Для работы алгоритма необходимо установить минимальные значения поддержки (min_sup) и достоверности (min_conf).
Читайте также
Как правило, минимальные пороги определяются экспериментальным путем. Но следует помнить об особенностях минимальных значений порогов:
- Если поддержка будет иметь большое значение, то алгоритм на выходе определит слишком очевидные правила. Поэтому не рекомендуется задавать поддержку более 20%.
- Если выбрать малое значение поддержки, то среди правил могут оказаться пары товаров, которые в действительности являются случайными. В этом случае смотреть необходимо на значение lift.
- Если достоверность имеет слишком малое значение, то вряд ли такую пару можно вообще считать правилом. Значение достоверности 7% больше похоже на случайность.
- Значение достоверности более 85% говорит о том, что такую пару товаров пользователи покупают практически всегда.
В итоге задача поиска ассоциативных правил решается в два этапа:
- поиск часто встречающихся элементов (support > min_sup);
- выявление правил из элементов, сформированных на первом шаге (confidence > min_conf).
Самый популярный и производительный data mining алгоритм поиска ассоциативных правил — это самообучающийся алгоритм Apriori.
Пакет arules содержит функции, реализующие работу Apriori. Провести анализ товарных пар можно через RStudio, но мы рассмотрим реализацию этого алгоритма в среде Power BI.
Читайте также
Подготовка данных для запуска алгоритма
Для корректной работы алгоритма необходимо предварительно обработать данные. От качества исходных данных зависит 80% результата работы алгоритма. К тому же, если у вас недостаточный объём исходных данных, вряд ли вы получите адекватные результаты.
Данные, которые подаются на вход, должны быть представлены в виде транзакционной таблицы, где каждая строка — это отдельная транзакция, а в столбцах содержится наименование купленного товара. В нашем случае это CSV-файл. Мы изменили наименования некоторых товаров, чтобы не нарушать конфиденциальность данных клиента.

Загружаем эти данные в Power BI:

Следите за эффективностью вашего маркетинга. Закажите
Отчётность в Power BIЗапуск алгоритма
Реализацию алгоритма Apriori осуществляем через R-скрипт, вызываемый в Power BI. Разберем подробнее работу скрипта.
- Подключаем библиотеки, которые потребуются для выполнения скрипта: library(Matrix)library(arules)library(readr). Не забудьте до начала запуска скрипта в Power BI убедиться, что у вас установлены необходимые пакеты. Например, вызовите install.packages(«arules») в R-studio для установки пакета «arules».
- Загруженные данные в Power Query в существующем виде не подходят для работы алгоритма Apriori в R, поэтому с помощью следующей функции данные преобразуются в объекты транзакций: data<-read.transactions(«адрес файла», header=TRUE, sep=«,», encoding=«UTF-8»).
- Поиск правил, которые формируют товарные пары, осуществляется с помощью функции apriori. В качестве параметров используются минимальные значения поддержки и достоверности, а также минимальна длина: datarules<-apriori(data, parameter = list(support=0.003, confidence=0.4, minlen=2)).
- Записываем полученные правила из предыдущего шага в понятный для Power Query формат данных: output<-DATAFRAME(datarules).
Если вам нужно вывести только первые N правил: output<-DATAFRAME(datarules[1:N]).
Все правила находятся в столбце Value, раскрываем столбец и сохраняем результаты:
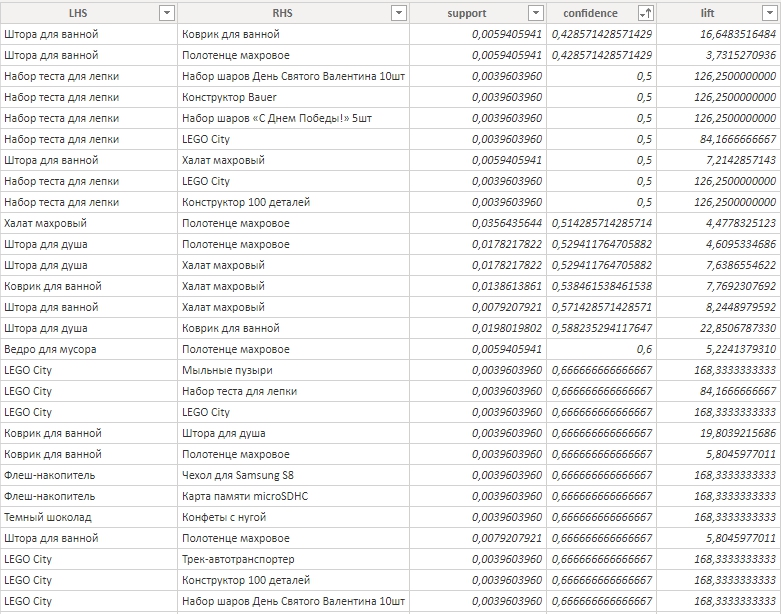
LHS (left-hand-side) — основной товар.
RSH (right-hand-side) — сопутствующий товар.
lift отражает уровень связи между переменными. Если lift < 1, то связь отрицательная, то есть товары являются товарами-заменителями, если lift = 1, то связь отсутствует, если lift > 1, то связь положительная.
Если в результате вы получили слишком очевидные правила или совершенно необъяснимые, изменяйте значения минимальных порогов.
Представление результатов
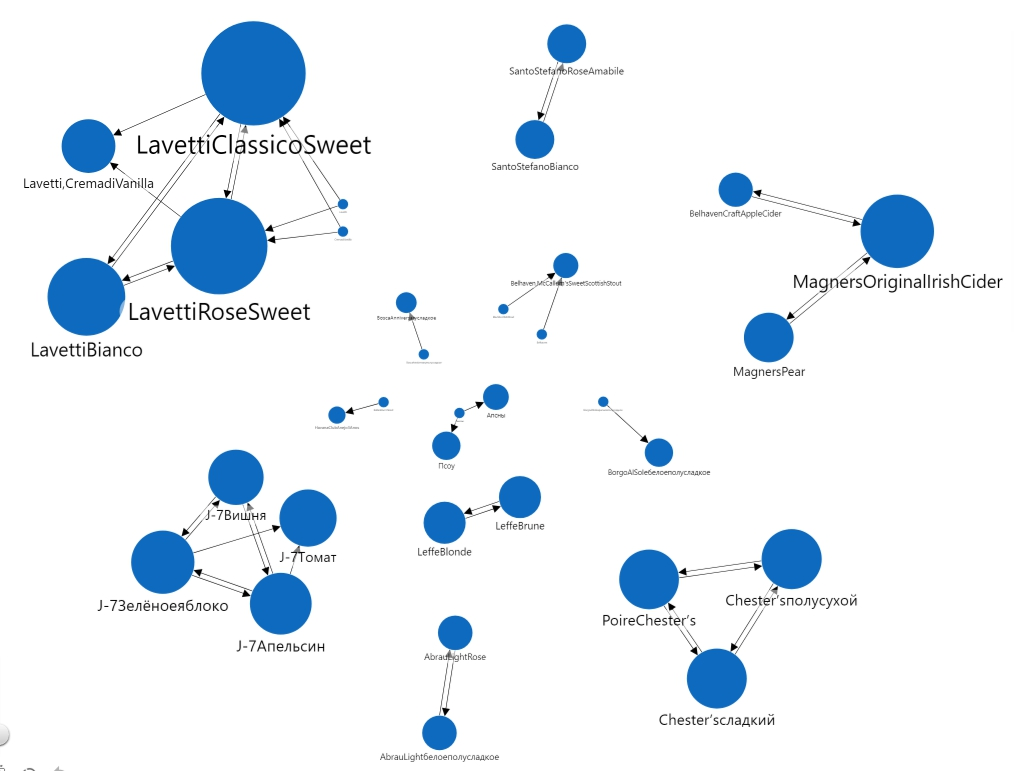
После сохранения полученных правил необходимо их представить в удобном виде. Для визуализации ассоциативных правил лучше использовать граф или дерево круговых диаграмм.
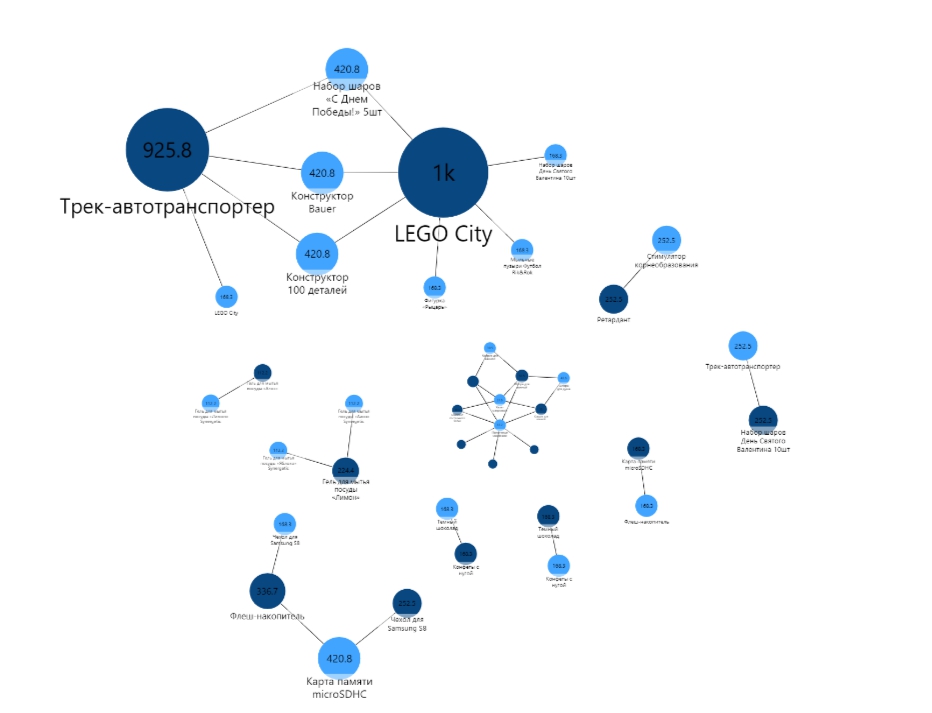
Анализ такого графа позволяет выделить категории товаров, исходя из поведения покупателей, а также определить роли товаров в этих категориях.
Основные товары — это самые популярные товары в каждой группе. Например, в группе № 1 такими товарами являются трек-автотранспортер и Lego City. Остальные товары являются сопутствующими.
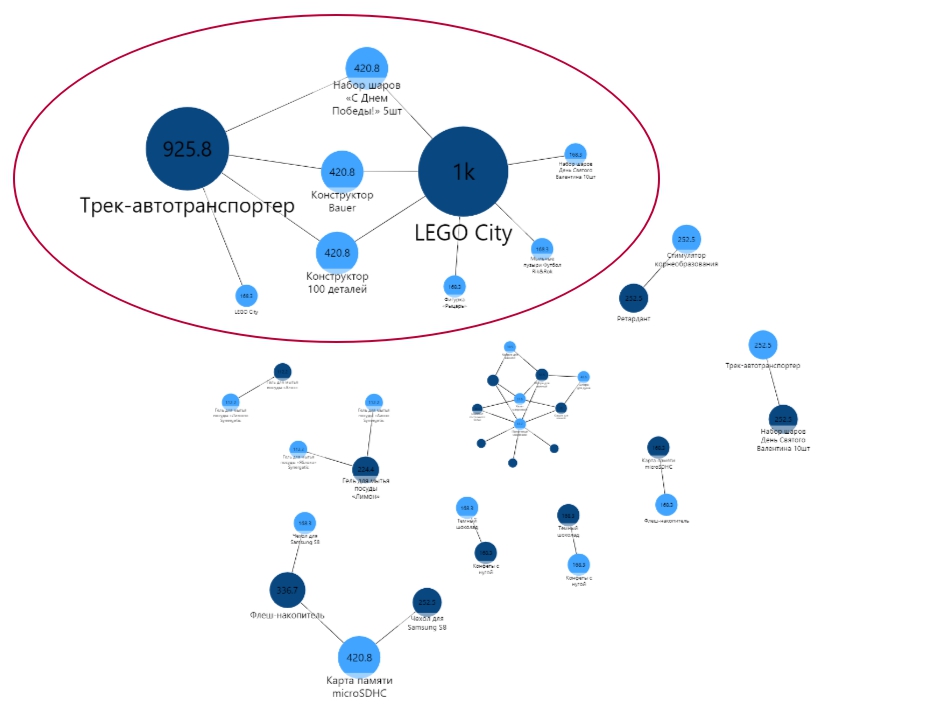
Товары-посредники — это товары, соединяющие между собой две группы товаров. Продажи между группами происходят именно через такие товары.
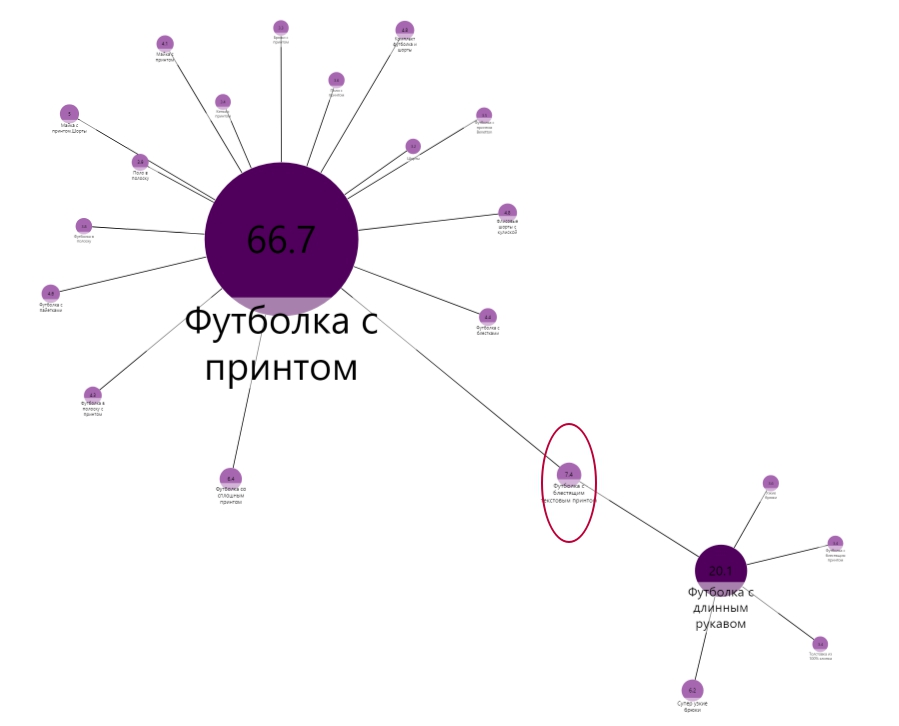
И ещё один граф для примера: